The Anti-Thesaurus:A Proposal For Improving Internet Search While Reducing Unnecessary Traffic Loads |
In the continual struggle between search engine administrators, index spammers, and the chaos that underlies knowledge classification, we have endless tools for "increasing relevance" of search returns, ranging from much ballyhooed and misunderstood "meta keywords", to complex algorithms that are still far from perfecting artificial intelligence. Proposal: there should be a metadata standard allowing webmasters to manually decrease the relevance of their pages for specific search terms and phrases. ================================= I operate several web sites. Among the many search strings bringing visitors in, of no use to either the searcher or me, are: 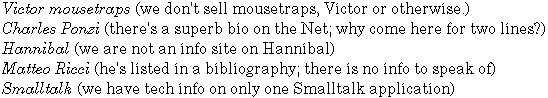 I am faintly embarrassed by drawing in these searchers, when I have no useful information for them. Their time was wasted – needlessly. Furthermore, they hog my bandwidth, and clog my log files with useless data. (With better search skills, they might never have arrived at my pages. But I'm not a member of the "they're so stoopid" school of thought. Anyway there are plenty of genius-level people who just aren't wired correctly for search.) Then there are the searchers I would just as soon not know about at all, like the ones looking for: stalking on the Internet The phrase that was bringing them in was "Marketing Myths Stalking the Internet". Potentially even a Google exact-phrase search would have led a searcher to that page, since Google treats "on" and "the" as stopwords, generally ignoring them even if they are within quote marks. A metadata tag to eliminate such irrelevant searches would be quite useful. E.g.: <meta name="nonwords" content="victor, ponzi, hannibal, matteo"> would eliminate numerous hits on my servers. I couldn't add "smalltalk" to the list, since that particular page actually does give Smalltalk information, even though it is secondary to the page's subject. (From an information science point of view, the present HTML META="keywords" tag is very loosely speaking a thesaurus, since it provides a place for alternate spellings of words, misspellings, related words – as well as words with similar meaning. That index spammers have widely abused it does not change that original intent. Thus my term, the "anti-thesaurus".) Will They Use It? The answer is: enough to make it worthwhile. Saving storage alone is of interest. If nothing else, every unwanted page I visit snarfs a small chunk of my disk storage. Many pages add up to a lot of snarfing. Techies have assured me that storage will soon cost $5 per terabyte at CompUSA – and that will take care of storage problems. Perhaps. On the other hand, millions of coders keep cranking out millions of lines of code. Billions of non-coders keep cranking out papers and email. Roger Gregory, who was project leader for Xanadu Green – and was giving thought to the whole planet's storage – saw it somewhat differently: "We concluded that there will never be enough storage." Yet an equally big payoff would come through reduced transmission loads. Wireless in particular has some rough years ahead, and I for one really don't want to download useless web pages at 19,600kbs. Also, returning to the robots.txt standard: it may be underused simply because it is a security breach (the file openly lists URLs that webmasters do not want visible through search engines). It is possible that many more webmasters would be using it properly, if not for that security problem. (Leaving a page out of the robots.txt file, a la "security by obscurity", is admittedly no guarantee of security. SE spiders could find the URL in another web site's unprotected logs, and crawl it anyway. But many webmasters consider that risk preferable to blatantly listing the URL right in robots.txt for anyone at all to see.) An Anti-Thesaurus is a much more limited security risk. There is little that can be learned from what sort of traffic a site's webmaster does not want. (Yes, one might suspect many things, by viewing the tag's keywords. But it's a pretty big jump from seeing the keywords a webmaster added to an nonwords tag, to predicting corporate strategy.) Will They Misuse and Abuse It? I don't see any obvious way to abuse such a tag on any major scale. That is, I can see plenty of ways to get cute – just as webmasters used to spend hundreds of largely-wasted hours trying to manipulate SEs through the META KEYWORDS tag. (But I haven't done any serious experimentation to look for major security flaws. Feedback welcome.) The Load On the Search Engines Notes 2. The "anti-thesaurus" should not be confused with "stop lists," which in information science usually refer to lists of "stop words" – common words such as "the" or "and", to exclude them completely from the search protocol for all searches. If one wants to quibble, I suppose the anti-thesaurus could be called a "content-provider-definable stop word list." But I'd just as soon leave "stop words" to the information retrieval professionals. December 19, 2001 -- an expansion of this paper, January 22, 2002 -- the example of five unwanted searches near the top of this page is now a graphic. (The page had become #1 on several search engines for "V*i*c*t*o*r m*o*u*s*e*t*r*a*p*s.) |
|
Please send comments to Nicholas Carroll Email: ncarroll@hastingsresearch.com http://www.hastingsresearch.com/net/06-anti-thesaurus.shtml © 1999-2002 Hastings Research, Inc. All rights reserved. |